
RAG + LLamaIndex + Replicate + Upstash = (ノ◕ヮ◕)ノ*:・゚✧
Published:

Well, when it comes to AI, I find the RAG approach quite useful for interacting with data.
Let’s consider it this way: you have a vast, immersive dataset lying somewhere. When you need to extract information from it, you have to search for it. This might take some time, depending on your data size.
Alternatively, you can use RAG with an LLM to communicate with it. Yes, you can talk to your data. And I think that is a great way to implement AI in your business solution.
I have some .txt files lying in one of my folders, and I want to interact with them. I’ll try to keep this as implementable in real life as much as possible.
I’ll use the following tools:
- Python
- I’ll use Python to write the code
- Upstash
- I’ll use Upstash’s vector index platform
- Huggingface
- I’ll use
all-MiniLM-L6-v2embeddings from Huggingface to transform data into vectors
- I’ll use
- Replicate
- I’ll use Replicate to run Meta’s latest
llama-2-70b-chatmodel
- I’ll use Replicate to run Meta’s latest
- LlamaIndex
- I’ll use LlamaIndex to create a pipeline using the above platforms
I’ll split this app into 2 parts. First, we need to create a vector index and store it in Upstash. In the second part, we’ll query the vector index to get relevant information and pass it to llama-2-70b-chat by running it in Replicate.
Let’s start with the first part and create a file called create_vector.py.
First of all, we need to get the embeddings from Huggingface.
from llama_index.embeddings.langchain import LangchainEmbedding
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.core import Settings
embeddings = LangchainEmbedding(HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2"))
Settings.embed_model = embeddings
It’s important that we set the embeddings as default by using Settings.embed_model.
Then, we need to set up a vector store using Upstash.
from llama_index.vector_stores.upstash import UpstashVectorStore
vector_store = UpstashVectorStore(
url=os.environ["UPSTASH_VECTOR_URL"], token=os.environ["UPSTASH_VECTOR_TOKEN"]
)
Okay, now we are ready to load the data from my local folder.
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(
input_dir="./data",
required_exts=[".txt"]
)
documents = reader.load_data(show_progress=True)
And now, we are at the last part. Let’s transform them into vectors and store them in Upstash.
from llama_index.core import StorageContext, VectorStoreIndex
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex.from_documents(documents, storage_context=storage_context)
Now, we need to create a vector index at Upstash’s website. For that, let’s go to the Upstash Console, and create a vector index with 384 dimensions. This part is important. 384 is not a magical number here. We are using all-MiniLM-L6-v2 to create vectors, and it creates a 384 dimensional vector space.
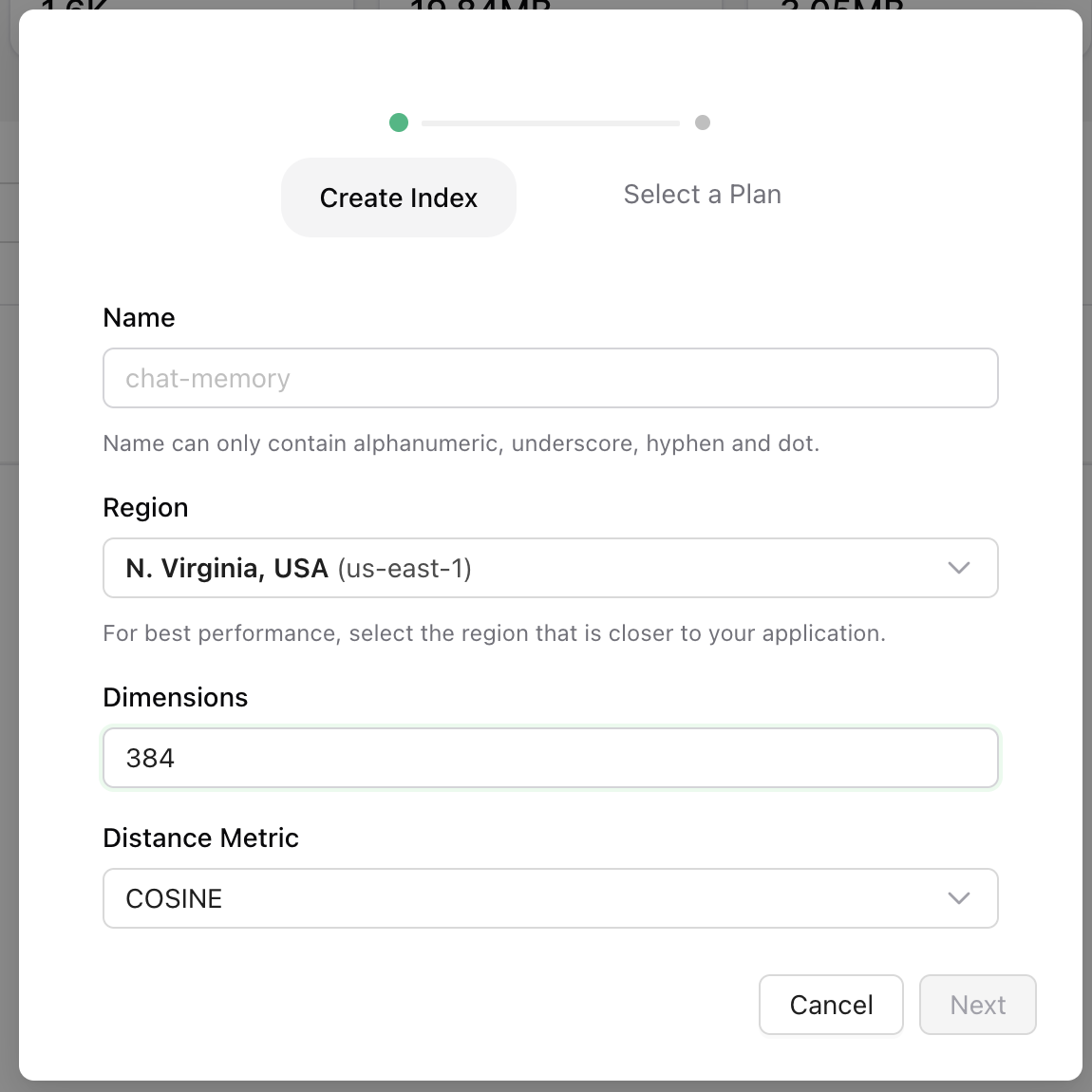
And once you run this script, you’ll have the vector index ready to query.
Now, let’s get into the second part, which is finding relevant information about the question and passing it to the model.
Let’s create a file called app.py and define our prompts.
from llama_index.core.prompts.prompts import SimpleInputPrompt
def get_prompts():
system_prompt = """[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as
helpfully as possible, while being safe. Your answers should not include
any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
If you don't know the answer to a question, please don't share false information.
Your goal is to provide answers relating to context that is given to you.<</SYS>>
"""
query_wrapper_prompt = SimpleInputPrompt("{query_str} [/INST]")
return system_prompt, query_wrapper_prompt
Now we can create our fundamental parts, which are the LLM, embeddings, and vector store connection.
from llama_index.llms.replicate import Replicate
from llama_index.embeddings.langchain import LangchainEmbedding
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.upstash import UpstashVectorStore
from llama_index.core.settings import Settings
def get_query_engine(system_prompt, query_wrapper_prompt):
llm = Replicate(
model="meta/llama-2-70b-chat:2d19859030ff705a87c746f7e96eea03aefb71f166725aee39692f1476566d48",
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
)
embeddings = LangchainEmbedding(HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2"))
Settings.embed_model = embeddings
Settings.llm = llm
vector_store = UpstashVectorStore(
url=os.environ["UPSTASH_VECTOR_URL"], token=os.environ["UPSTASH_VECTOR_TOKEN"]
)
index = VectorStoreIndex.from_vector_store(vector_store)
query_engine = index.as_query_engine(streaming=True)
return query_engine
Everything is straightforward for now. We’ve created the LLM using the Replicate API. We passed the model name and prompts to the system. Then, we created the same embeddings we used for vector index creation. Then we set them as default using Settings.
Then we connected to the Upstash Vector and got the index as a query engine. Now we can connect those parts.
system_prompt, query_wrapper_prompt = get_prompts()
query_engine = get_query_engine(system_prompt, query_wrapper_prompt)
response_stream = query_engine.query("<question>")
response_stream.print_response_stream()
Everything looks good so far. Now we can run this script like this.
UPSTASH_VECTOR_URL="<upstash_vector_url>" UPSTASH_VECTOR_TOKEN="<upstash_vector_token>" REPLICATE_API_TOKEN="<replicate_api_token>" python app.py
Now, you can debug the model as it’s running by going to the Replicate dashboard, and you should see the output in the terminal as it’s coming from the model.
Conclusion
Well, I love AI when it comes to using it as an assistant. My thoughts might change in the future if it takes my job (^▽^).
But overall, this was a great journey for me. I’ve learned about embeddings, external vector stores, and how to use them without losing data. LlamaIndex is a great framework to start with if you want to learn stuff. They have great integration with other tools like Replicate and Upstash in this case.
As a software engineer, I need to keep myself up-to-date with the constant changes in the industry, and AI was one of them. I don’t know how to build a model, but I’m not sure if I want to. I just want to use it in my daily programming life. And like I said, I think RAG is a great use-case for this. Now I can try to host a pretrained model in the cloud and then use it for my experiments.
Thank you for reading.